Reranker에 대해 3편에 걸쳐 다뤄볼 예정이에요.
이번 포스팅에서는 Retriever만으로는 부족한 이유, 그리고 Reranker의 역할에 대해서 알아보겠습니다.
<Reranker 완전 정복 목차>
☑️ Part 1 (이번 글): Retriever만으로 부족한 이유, 그리고 Reranker가 필요한 이유
☑️ Part 2: Reranker 모델의 종류와 RAG(Retrieval-Augmented Generation)과의 연계
☑️ Part 3: 최신 연구 동향과 실무 적용 사례
1. Retriever만으로는 왜 부족할까?
요즘 검색 시스템에서 Retriever는 벡터 임베딩(Vector Embedding)을 활용해 의미 기반 검색을 할 수 있어요.
그렇다면 Retriever만으로도 충분하지 않을까요?
사실 그렇지 않아요. Retriever는 검색 속도가 빠르지만 검색된 문서의 정밀한 재정렬이 필요해요.
🔻 Retriever의 한계
Retriever는 보통 Bi-encoder 방식을 사용해요.
- 문서와 쿼리를 각각 독립적으로 벡터로 변환한 뒤,
- 두 벡터 간의 유사도를 비교해서 상위 K개의 문서를 선택하는 방식이에요.
이 방식은 빠르게 검색할 수 있지만 문맥을 깊이 고려하지 못하는 한계가 있어요.
예제: "무지개의 색깔은 총 몇가지?"
- Retriever는 벡터 임베딩을 기반으로 "빨주노초파남보 7가지"를 언급한 문서를 찾아줄 수 있어요.
- 하지만 검색된 문서가 긴 문서라면?
- "무지개의 색은 총 7가지이며, 이는 빨주노초파남보다."라는 내용이 문서 중간이나 끝에 위치하면,
- LLM이 이를 제대로 활용하지 못할 수 있어요.
"Lost in the Middle" 문제
최근 연구에 따르면 LLM은 컨텍스트의 상위권에 위치한 정보를 더 잘 활용한다고 해요.

- 즉, 검색된 문서 안에 중요한 정보가 있어도,
- 중간이나 끝부분에 있다면 제대로 활용되지 않을 가능성이 커요.
그렇기 때문에 Retriever만으로는 부족하고, Reranker가 필요해요.
2. Reranker는 어떤 역할을 할까?
Reranker는 Retriever가 찾아준 문서를 더 정밀하게 분석해서 순위를 재조정하는 역할을 해요.
🔻 Reranker의 역할
- Retriever가 찾은 Top-K 문서들을 입력으로 받음
- 질문과 문서를 함께 입력으로 넣고, 문맥을 분석하여 유사도 점수를 새롭게 계산
- 점수가 높은 문서를 최상단에 배치
이렇게 하면 LLM이 보다 정확한 정보를 활용할 수 있어, 답변의 질이 향상돼요.
3. Retriever vs. Reranker 비교
| Retriever | Reranker | |
| 목적 | 빠르게 관련 문서를 찾음 | 검색된 문서를 정교하게 평가 후 재정렬 |
| 기술 | 벡터 임베딩, 내적 연산 | 트랜스포머 기반 NLP 모델 |
| 속도 | 빠름 (수천만 개 문서 처리 가능) | 느림 (고도의 연산 필요) |
| 정확도 | 중간 (의미적 분석 부족) | 높음 (문맥까지 고려하여 정밀 분석) |
| 입력 방식 | 문서와 쿼리를 각각 벡터로 변환 | 문서와 쿼리를 하나의 입력으로 함께 처리 |
| 활용 사례 | 벡터 검색, 실시간 추천 시스템 | 검색 결과 재정렬, 문서 랭킹 최적화 |
Retriever는 속도, Reranker는 정확도에 초점을 맞춰요.
그래서 두 기술을 조합하면 빠르면서도 정확한 검색 시스템을 만들 수 있어요.
4. Retriever와 Reranker를 함께 사용하면? (Two-stage Retrieval)
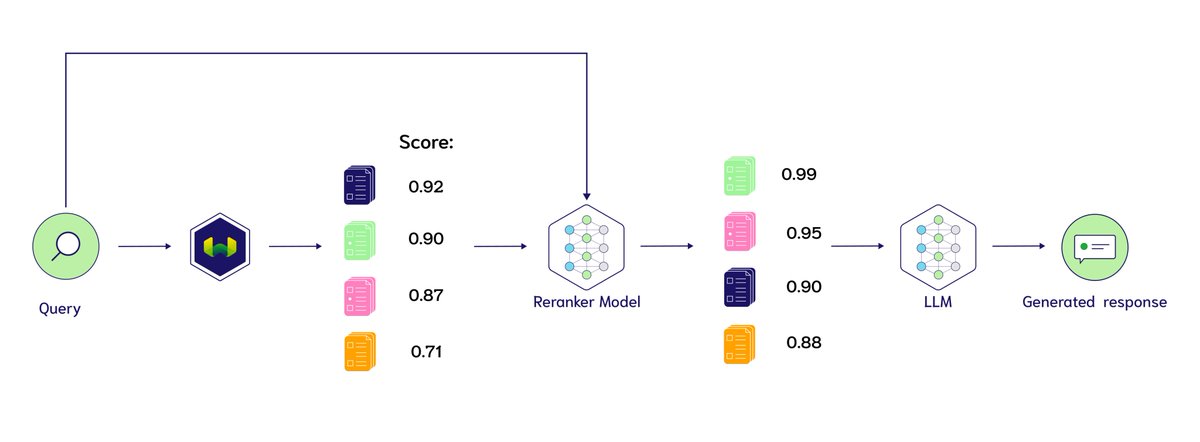
Retriever와 Reranker를 함께 사용하면 빠르면서도 정확한 검색 시스템을 구축할 수 있어요.
1단계: Retriever(Bi-encoder 기반) - 빠르게 후보 문서 검색
- 벡터 임베딩을 사용해 대량의 문서 중에서 가장 관련성이 높은 Top-K개 문서를 찾음
- 빠른 검색이 가능하지만 문맥까지 완벽하게 고려하지는 못함
2단계: Reranker(Cross-encoder 기반) - 검색된 문서의 순위 재조정
- Top-K 문서와 질문을 함께 입력으로 넣고, 문서의 실제 관련성을 평가
- 문맥을 고려해 최적의 순서로 정렬
이 방식은 검색 속도를 높이면서도 최종적으로 가장 정확한 문서를 상위에 배치할 수 있는 방법이에요.
5. Reranker의 작동 방식 (Cross-encoder 예제)
Reranker는 질문과 문서를 하나의 입력으로 넣고 트랜스포머 기반 모델을 통해 문맥적 유사도를 평가해요.
아래는 Hugging Face의 CrossEncoder 모델을 활용한 리랭킹 예제예요.
from sentence_transformers import CrossEncoder
# Cross Encoder 모델 불러오기
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
# 검색 결과 (Retriever가 반환한 문서들)
query = "딥러닝 기반 추천 시스템 최신 연구"
documents = [
"배고플 때 먹을 수 있는 간단한 음식",
"김oo 교수가 최근에 발표한 BERT를 활용한 자연어 처리 연구",
"딥러닝을 활용한 최신 추천 시스템 연구가 등장했다",
]
# 쿼리-문서 쌍을 만들고, 관련도 점수 계산
pairs = [(query, doc) for doc in documents]
scores = model.predict(pairs)
# 점수 기반으로 문서 정렬
reranked_results = sorted(zip(documents, scores), key=lambda x: x[1], reverse=True)
# 출력
for doc, score in reranked_results:
print(f"문서: {doc} | 점수: {score:.4f}")☑️ 실행 결과
문서: 딥러닝을 활용한 최신 추천 시스템 연구가 등장했다 | 점수: 7.8728
문서: 김oo 교수가 최근에 발표한 BERT를 활용한 자연어 처리 연구 | 점수: 7.8389
문서: 배고플 때 먹을 수 있는 간단한 음식 | 점수: 6.9237
Reranker가 "추천 시스템 + 딥러닝"을 가장 중요하게 판단해서 가장 관련성이 높은 문서를 최상단에 배치했어요.
6. 결론: Retriever와 Reranker를 조합해야 하는 이유
- Retriever(Bi-encoder)는 빠른 검색이 가능하지만 문맥을 깊이 분석하지 못해요.
- Reranker(Cross-encoder)는 문맥까지 고려해서 정확한 유사도 평가가 가능하지만 연산량이 많아요.
- 이 두 가지를 조합하면 빠르면서도 정확한 검색 시스템을 구축할 수 있어요.
다음 편에서는?
- Part 2: Reranker 모델의 종류 & RAG(Retrieval-Augmented Generation)와의 연계
- Part 3: 최신 연구 동향 & 실무 적용 사례
다음 글에서는 Reranker 모델의 종류 & RAG(Retrieval-Augmented Generation)와의 연계에 대해 살펴볼게요!